


I. Introduction▲
I-A. L'utilité d'une architecture en couches▲
Une architecture en couches est une architecture dont les responsabilités sont reparties sur plusieurs « briques ». Elles ont donc un rôle bien défini. Ainsi, l'exemple qui sera utilisé dans cet article ainsi que dans la plupart des applications, est composé d'une couche d'accès aux données (DAL - Data Access Layer), une couche de logique métier (BLL - Business Logic Layer), une éventuelle couche de service qui permet d'exposer des services au monde et éventuellement une couche de présentation.
De premier abord, cela peut sembler assez lourd comme découpage. Cependant l'utilité est manifeste.
Prenons le cas d'une petite application qui me permet de visualiser des objets stockés dans un fichier XML. Tout est codé dans le code-behind dans mon interface graphique. Si je souhaite dorénavant stocker mes données dans une base SQL, cela impacte tout mon code ! Avec un découpage par couches, je n'ai qu'à changer la couche d'accès aux données par la nouvelle version supportant le SQL. On peut également bâtir plusieurs couches de présentation pour une même logique sous-jacente (un accès en ASP.Net, un par WebServices, un dans une console, un dans une application Winform, un en Silverlight, un en WPF et éventuellement d'autres technologies).
C'est également intéressant pour les tests unitaires : un test unitaire doit tester une toute petite portion de code qui a une responsabilité précise. Lorsqu'aucune séparation n'existe, on se retrouve à effectuer des tests sur l'interface graphique pour vérifier que l'accès en base fonctionne, pas trop unitaire tout ça ! Avec une architecture en couche, chaque couche peut-être isolée et testée indépendamment. Ainsi, on peut tester uniquement le code métier, uniquement l'accès en base, etc.
Un point important dans le découpage en couches, c'est que celui-ci a un sens ! Une couche ne doit connaître que la couche immédiatement en dessous d'elle. La couche de présentation ne se préoccupe pas de la couche d'accès aux données, elle se préoccupe uniquement de la couche Business. La couche Business, elle, ne se préoccupe pas de la couche de présentation, mais uniquement de celle d'accès aux données. La couche d'accès aux données ne se préoccupe d'aucune autre couche.
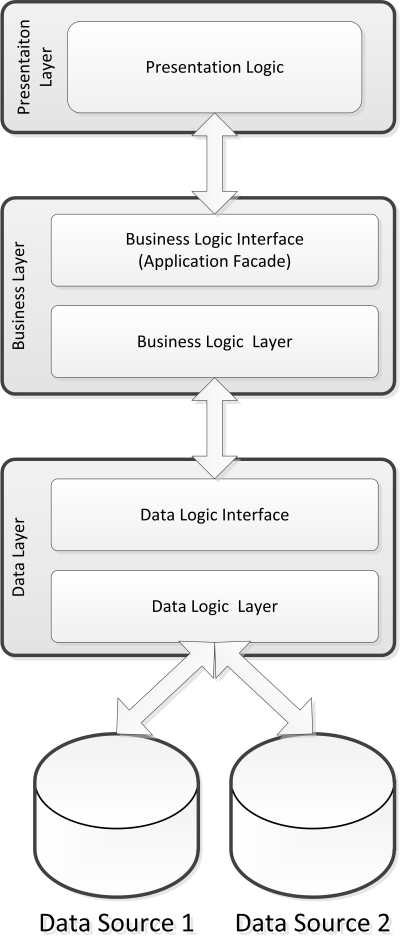
I-B. L'utilité du découplage▲
Si je reprends l'exemple de mon application ci-dessus, lorsque je compile la couche Business, elle va référencer la couche d'accès aux données. Ainsi, si je dois changer de couche d'accès aux données, il faut que je recompile l'application.
Le découplage se base sur des interfaces. Une couche publie ce qu'elle est capable de faire en implémentant une interface. Dans l'exemple précédent, la couche d'accès à une (ou plusieurs) interface qui est le contrat entre elle et la couche business. Ainsi, la couche Business possède une référence vers quelqu'un qui implémente l'interface (elle ne sait pas forcément qui), mais elle ne s'en préoccupe pas. Ainsi elle ne fait pas de référence directe vers la couche d'accès et la couche d'accès peut être changée sans recompiler l'application.
Cela permet également l'utilisation de mocks dans les tests unitaires. Un mock est une classe qui implémente la même interface que la classe réelle, mais qui renvoie de fausses données. Ainsi si on veut tester unitairement la couche Business, on crée un mock de la couche d'accès aux données. Ce mock ne fait pas vraiment un accès à la base, il est juste chargé de renvoyer des données de test qui vont bien pour le test unitaire(pour tester la règle métier par exemple).
I-C. L'injection de dépendances▲
Dans le paragraphe précédent, il y a une information que j'ai volontairement passée sous silence. Si la couche Business ne se préoccupe pas de la couche DAL, qui instancie alors cette dernière ?
La réponse est : le conteneur d'injection de dépendances ! C'est lui qui fait la glu entre les différents éléments et qui gère la durée de vie de ceux-ci.
Dans notre application exemple, il faut tout d'abord initialiser le conteneur, c'est-à-dire faire l'association entre un contrat et une implémentation. Cela peut se faire dans le code (présente un intérêt limité, car nécessite une recompilation pour faire un échange d'implémentation) ou par un fichier de configuration.
Par la suite, l'interface graphique de notre application se lance de manière traditionnelle, elle demande au conteneur « j'ai besoin d'une instance de couche business », la couche lui est retournée par le conteneur, elle peut désormais faire parvenir sa requête à la couche Business. Da manière analogue la couche business demandera une couche d'accès aux données au conteneur pour traiter la requête qu'elle vient de recevoir.
Nous allons utiliser Unity pour effectuer ce travail. Il existe d'autres conteneurs (notamment Spring.Net), mais ils ne seront pas abordés ici. D'ailleurs, Philipe Vialatte a écrit un article pour présenter ce principe avec les différents conteneurs existants Lien vers l'articleLien vers l'article
I-D. Présentation de Unity▲
Microsoft Unity Application Block est un framework qui fait partie des Patterns & Practices de Microsoft. C'est donc un outil suggéré par Microsoft pour un développement plus propre.
D'après le site officiel, Unity est un conteneur d'injection de dépendances, de poids léger, extensible et aidant à la construction d'architectures découplées. Ça tombe bien, c'est ce que l'on veut !
La documentation se trouve sur MSDN : Documentation MSDNDocumentation MSDN
Le site du projet sur CodePlex :Projet sur CodeplexProjet sur Codeplex
L'installation est relativement aisée puisqu'il suffit de lancer l'exécutable.